Degui Adil / Getty Images
It is often said that the difference between science and superstition is that science is reproducible. Unfortunately, many scientific papers aren’t, making them about as reliable as superstition.
Since the mid-1600s, the output from a typical scientific study has been an essay-style journal article describing the results. But today, in fields ranging from astronomy to microbiology, much of the technical work for a journal article involves writing code to manipulate data sets. If the data and code are not available, other researchers can’t reproduce the original authors’ work and, more importantly, may not be able to build upon the work to explore new methods and discoveries.
Thanks to cultural shifts and funding requirements, more researchers are warming up to open data and open code. Even 100-year-old journals like the Quarterly Journal of Economics or the Journal of the Royal Statistical Society now require authors to provide replication materials—including data and code—with any quantitative paper. Some researchers welcome the new paradigm and see the value in pushing science forward via deeper collaboration. But others feel the burden of learning to use distribution-related tools like Git, Docker, Jupyter, and other not-quite words.
“Data not available”
Daniella Lowenberg, principal investigator of the Make Data Count initiative, describes the ideals to which these data-sharing requirements aspire. “We want a world where data are routinely being used for discovery, to advance science, for evidence-based and data-driven policy,” she says. In some places, the future is already here. “There are data sets that drive entire fields,” she says, and “the field of research would not be where it is without these open data sets that are driving it.” As an example, she points to this data set of the wood density of 16,468 trees, which has been downloaded over 17,000 times.
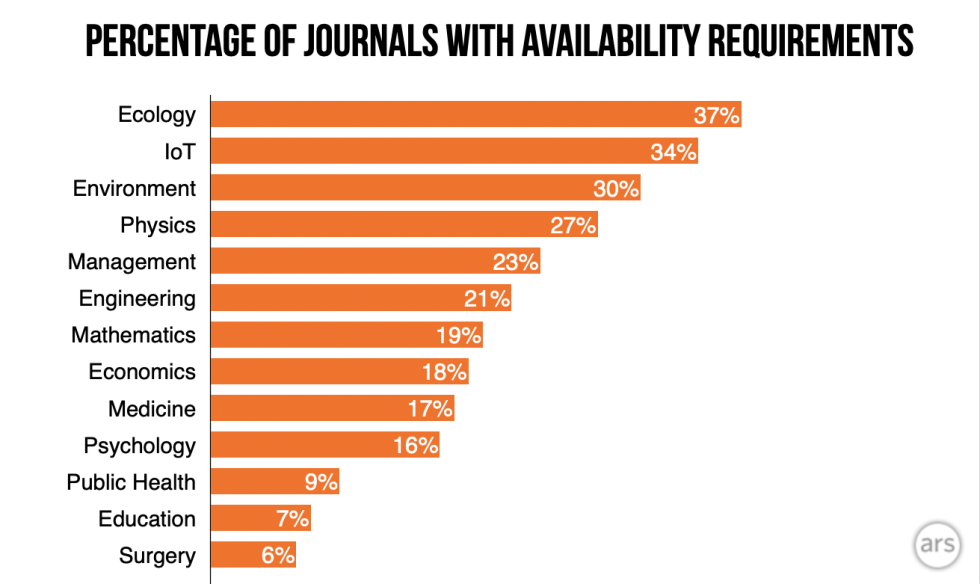
With that ideal in mind, journal editors increasingly make publication contingent upon open data and code. I checked about 2,700 journals published by Springer, one of the largest publishers of academic journals, for submission guidelines that state that authors must make all materials like data and code available.
The results suggest that open data and code is more of a custom in some fields than others. Among ecology journals, 37 percent have an availability requirement, while only 7 percent of surgery and 6 percent of education journals do. Other fields are between these extremes, with 16 to 19 percent of management, engineering, physics, economics, general medicine, and psychology journals stating such a requirement.
Ben Klemens
These sharing requirements are often held to an “available upon request” standard. But requests can go unheeded.
From 2017 through 2019, Tsuyoshi Miyakawa, the editor-in-chief of the journal Molecular Brain, replied to 41 article submissions by requesting that the authors provide their complete source data for review, as per the stated policy of the journal. Only one author did so.
The journal Science has had a policy that data and materials like code must be available upon request. Victoria Stodden and her co-authors tested this system. Out of 204 papers they selected from the journal, Stodden’s team successfully accessed materials for 89 articles; requests to the authors of the other 115 received no reply, unfulfilled promises, fruitless redirections, or a sometimes aggressive refusal.
Based on his efforts to replicate papers from other statisticians, Thomas Lumley, a professor of biostatistics at the University of Auckland in New Zealand, says of the phrase data available upon request: “When people put it in their papers, what they typically mean is ‘data not available.'”
As a result, an increasing number of funders and journals now require that researchers have a formal plan for publishing their data.
The National Institutes of Health (the NIH) gave over $30 billion in competitive research grants in 2020, and every grant application with a data component had to include a data management and sharing plan. Applicants are encouraged to deposit their work in established repositories, such as the NIH’s database of Genotypes and Phenotypes (dbGap). If you would rather have a piece of the several billion dollars in grants awarded by the National Science Foundation every year, you will also need a data management plan.