The field of artificial intelligence (AI) has made astonishing progress in recent years, mastering an increasing range of tasks that now include Atari video games1, board games such as chess and Go2, scientific problems including protein-folding3 and language modelling4. At the same time, success in these narrow domains has made it increasingly clear that something fundamental is still missing. In particular, state-of-the-art AI systems still struggle to capture the ‘common sense’ knowledge that guides prediction, inference and action in everyday human scenarios5,6. In the present work, we focus on one particular domain of common-sense knowledge: intuitive physics, the network of concepts that underlies reasoning about the properties and interactions of macroscopic objects7. Intuitive physics is fundamental to embodied intelligence, most obviously because it is essential to all practical action, but also because it provides one foundation for conceptual knowledge and compositional representation in general8. Despite considerable effort, however, recent advances in AI have yet to yield a system that displays an understanding of intuitive physics comparable to that of even very young children.
To pursue richer common sense physical intuition in AI systems, we take, at multiple points in our work, inspiration from developmental psychology, where the acquisition of intuitive physics knowledge has been an intensive focus of study9,10,11,12. We build a deep-learning system that integrates a central insight of the developmental literature, which is that physics is understood at the level of discrete objects and their interactions. We also draw on developmental psychology in a second way, which relates to the problem of behaviourally probing whether an AI system (or in the case of developmental psychology, an infant or child) possesses knowledge of intuitive physics.
In developing behavioural probes for research on children, developmental psychologists have based their approach on two principles. First, that the core of intuitive physics rests upon a set of discrete concepts11,13 (for example, object permanence, object solidity, continuity and so on) that can be differentiated, operationalized and individually probed. By specifically targeting discrete concepts, our work is quite different from standard approaches in AI for learning intuitive physics, which measure progress via video or state prediction14,15,16 metrics, binary outcome prediction17, question-answering performance18,19 or high reward in reinforcement learning tasks20. These alternative approaches intuitively seem to require an understanding of some aspects of intuitive physics, but do not clearly operationalize or strategically probe an explicit set of such concepts.
The second principle used by developmental psychologists for probing physical concepts is that possession of a physical concept corresponds to forming a set of expectations about how the future can unfold. If human viewers have the concept of object permanence21, then they will expect that objects will not ‘wink out of existence’ when they are out of sight. If they expect that objects will not interpenetrate one another, then they have the concept of solidity22. If they expect that objects will not magically teleport from one place to another but instead trace continuous paths through time and space, then they have the concept of continuity11. With this conceptual scaffolding, a method for measuring knowledge of a specific physical concept emerges: the violation-of-expectation (VoE) paradigm21.
Using the VoE paradigm to probe for a specific concept, researchers show infants visually similar arrays (called probes) that are either consistent (physically possible) or inconsistent (physically impossible) with that physical concept. If infants are more surprised by the impossible array, this provides evidence that their expectations, derived from their knowledge of the probed physical concept, were violated. In this paradigm, surprise is putatively measured via gaze duration, but see refs. 23,24,25 for further discussion. As an example, consider the concept of continuity (depicted in Fig. 1): objects trace a continuous path through time and space. For the possible probe (Fig. 1, first row), researchers26 showed an object moving horizontally behind a pillar, being occluded by that pillar, subsequently emerging from occlusion, and travelling towards a second pillar, where it was again occluded behind that pillar and emerged from occlusion one final time. In the impossible probe (Fig. 1, third row), when the object is occluded by the first pillar, it does not emerge from occlusion immediately. Instead, after some delay, the object emerges from behind the second pillar – never appearing in the space between the two pillars and thus seeming to teleport from one pillar to the other. Experiments with infants have shown that by the age of 2.5 months, they gaze longer at an object that teleports between two screens than an object that moves continuously from one screen to the next26. This same strategy has been used by developmental researchers to accumulate strong evidence that infants acquire a wide range of distinct physical concepts9,10,11,12 within the first year of life.
Example probes adapted from ref. 26 to assess the physical concept of continuity11,69: objects trace a continuous path through time and space. Each row corresponds to one temporally downsampled video in a probe tuple. Checkered backgrounds were used as a cue for depth and to introduce visual diversity of our stimuli. Actual videos consist of a total of 15 frames. The top two rows are physically possible probes and the bottom two rows are physically impossible probes. Physically possible probes: in the first physically possible probe (first row), a ball rolls behind two occluders. In the second possible probe (second row), no ball is present. Physically impossible probes: these probes are formed by splicing parts of the physically possible probes into impossible events. In the first impossible probe (third row), the ball rolls behind the first occluder and emerges from the second occluder, never appearing between the two occluders. The second impossible probe (fourth row) has the opposite structure: the ball appears between the two occluders, but was never seen rolling behind the first occluder or rolling out of the second occluder.
In previous work27, we introduced a machine-learning video dataset designed to systematically test how well models can learn specific physical concepts (see Discussion for comparison against similar datasets developed in parallel28 and subsequently29). Our original dataset contained procedurally generated VoE probes that assess acquisition of a set of physical concepts, constructed so that no individual video frame could explain any resulting VoE effect. In the present work, we introduce a much richer video corpus, the Physical Concepts dataset (URL for dataset will be filled in here). This new dataset contains VoE probe videos targeting five physical concepts that have been identified as central in the developmental psychology literature. The first three, continuity (Fig. 1), object persistence (Supplementary Fig. 1) and solidity (Supplementary Fig. 2), were introduced above. The fourth concept, ‘unchangeableness’ (refs. 9,30, Supplementary Fig. 3), captures the notion that certain object properties (for example, shape) do not change. The fifth and final concept, directional inertia (a more specific form of the inertia principle tested in ref. 31, Supplementary Fig. 4), involves the expectation that moving objects undergo changes in direction consistent with the principles of inertia. As detailed in Methods, each video showing a violation of these physical principles is matched with a corresponding video that provides a physics-consistent baseline, maintaining precisely the same single-image statistics across videos. Our probe videos were based on stimuli used in specific developmental psychology experiments, but we made changes to event details introduced to enhance experimental control without changing the span of physical concepts probed.
Critically, the Physical Concepts dataset also includes a separate corpus of videos intended as training data. These videos show a wide variety of procedurally generated physical events (Fig. 2 and Methods) involving objects similar to those involved in the probe videos, among others, but never showing the specific events involved in the test probes. Readers are encouraged to view examples in video format: http://tiny.cc/phys_concepts_training.

Example training videos (temporally downsampled, actual videos contain 15 frames). Scenes are constructed procedurally with composable interactions: objects added to a scene are either initialized completely randomly or target preexisting objects in the scene. The camera starts from a fixed location and drifts randomly over time.
Equipped with this dataset and evaluation framework, we now turn to the primary objective of the present research: to build a model capable of learning intuitive physics and dissect what enables that capacity. Our architecture is inspired by accounts from developmental psychology which posit that three object-centric processes underpin infant intuitive physics behaviour9. We leverage recent advances in AI to instantiate these systems in a model that we nickname PLATO, for Physics Learning through Auto-encoding and Tracking Objects. First and foremost is the process of object individuation11. Object individuation carves the continuous perceptual input of vision into a discrete set of entities, where each entity has a corresponding set of attributes. In PLATO, each segmented video frame is decomposed into a set of object codes via a perception module (Fig. 3a–c), thus implementing a mapping from visual input to individuated objects. PLATO does not learn to segment the scene (that task is accomplished via ground truth segmentation masks from the dataset), but given a segmented object learns a compressed representation. Second, object tracking (or object indexing) assigns an index to each object, enabling a correspondence between object percepts across time32,33,34 and computation of dynamic properties (Fig. 3b,c). In PLATO, the object codes are accumulated and tracked over frames in an object buffer (Fig. 3d). This is accomplished again by virtue of ground truth segmentation masks which provide a correspondence between objects across frames. The final component is relational processing of these tracked objects. This is inspired by the idea, proposed in developmental psychology, of a ‘physical reasoning system’9, which dynamically processes representations of objects, yielding new representations that are inflected by their relationship to and interactions with other objects. In PLATO, we learn interactions (Fig. 3d) between the object memory (a slotted object-based long short-term memory (LSTM)35) and the history of object percepts (the object buffer) to produce per-object predictions for the next video frame and update the object-based memory. We train PLATO on a next-step prediction task and evaluate its performance on our suite of intuitive physics probes. Although PLATO is unique in its detailed inspiration from the developmental literature and the domain to which it is applied, it is important to note that there are various similar models and proposals that prioritize object-centric representations, interactions and computations (for example, refs. 20,36,37).
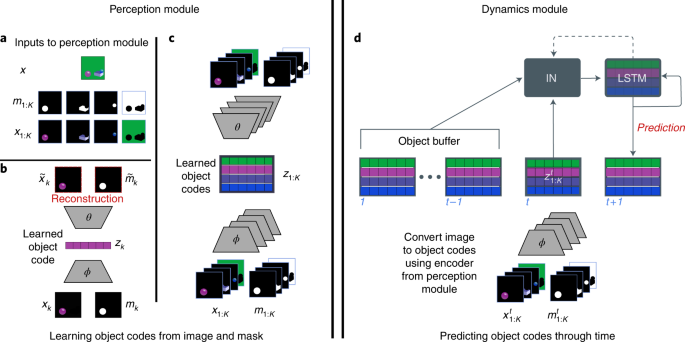
PLATO consists of two components: the perception module (left) and the dynamics predictor (right). The perception module is used to convert visual input into a set of object codes. These object codes are used by the dynamics modules to predict future frames. a, The perception module takes as input an image x and an associated segmentation mask m1:K. Taking the elementwise product yields a set of images of just the visible parts of each object: x1:K. b, Given an object image-mask pair, the perception module produces an object code zk via an encoder module ϕ. The object code is decoded back into a reconstruction of the object image-mask pair via the decoder module θ. The discrepancy between the reconstruction and the original image-mask pair is used to train the parameters of ϕ and θ such that zk comes to represent informative aspects of each object image-mask pair. c, After training, an entire image can be reconstructed via a set of object codes z1:K by independently running each image-mask pair through ϕ and decoding via θ. d, The dynamics module is trained on sequence data produced by running videos (and their segmentation masks) through the pretrained encoder ϕ. The dynamics module must predict the object codes in the next frame given the object codes in the current frame ({z}_{1:K}^{t}) and an object buffer of the codes in the preceding frames ({z}_{1:K}^{1:t-1}). The dynamics module comprises two trainable components: a ‘slotted’ object-based LSTM and an interaction network (IN). Predictions are made by computing interactions from each slot in the LSTM’s previous state (dotted arrow) to every other slot in the LSTM and all input object codes and buffers ({z}_{1:K}^{1:t}). The resulting interaction is used to make objectwise predictions and updates to the LSTM.
To foreshadow our results, we find that PLATO displays strong VoE effects across all five concept-probe categories in our dataset. By contrast, carefully controlled comparison models that lack object-centred representations fail to achieve above-chance results on the evaluation suite, even when furnished with more computational capacity. Furthermore, we report that our object-centred model, when given object segmentation and tracking, can develop robust VoE effects with a surprisingly small amount of training data, equivalent to 28 h of visual experience. Finally, we evaluate our model’s behaviour on unseen objects and events as a strong test of generalization. We test PLATO, without additional training, on an independently developed test set, and find that it continues to display robust VoE effects in this generalization setting.
Results
Models
To implement the object-centric approach, our model comprises two main components: a feedforward perceptual module (Fig. 3a–c) and a recurrent dynamics predictor with per-object memory (Fig. 3d). The perceptual module takes as input an image and segmentation mask—we discuss later how segmentations can also be learned from scratch from visual data—and converts these into a vector embedding using standard deep-learning auto-encoding methods (Fig. 3a–c and Methods). In effect, the perceptual module parses the high-dimensional visual input into a small set of discrete object codes.
The dynamics predictor centres on a structured recurrent neural network we developed called an InteractionLSTM (Fig. 3d: ‘IN’ and ‘LSTM’ boxes; Methods). This takes as input the history of single-frame object-level embeddings (Fig. 3, ‘object buffer’) and predicts the set of object codes at the next timestep (Fig. 3, ‘prediction’).
We hypothesized, on the basis of the insights provided by developmental psychology, that the involvement of object-level coding would be critical to the acquisition of intuitive physics concepts and corresponding VoE effects. To evaluate this claim, we constructed a well-matched object-agnostic ‘flat’ model as a baseline for comparison. For this, we took each component in PLATO that used a set of object codes, and replaced that set with a single vector embedding for the entire scene (Methods). We investigate two versions of the resulting flat model on the basis that we can match either the number of tunable parameters in PLATO or the number of units representing each video frame. In the flat equal parameters (FEP) baseline, the flat embedding has the same number of dimensions (16) as one of PLATO’s single-object codes. This model has the same number of learnable parameters in the dynamics predictor as PLATO, but reduced capacity for representing images in the perceptual module. In the second version, flat equal capacity (FEC), we give the flat code the same capacity for representing images in the perceptual model (a single 128-dimensional vector, given that PLATO contains eight 16-dimensional object-code slots). In this case the dynamics predictor contains approximately four million more parameters than PLATO (see Methods for full implementational details).
Training and testing
For all models, training consisted of two phases. In the first phase (Fig. 3a–c), the perceptual module was trained to reconstruct individual images from the training data (see Methods for loss function and other details). After this phase, the weights within the perceptual module were fixed, yielding an encoder that could produce object (or flat) codes from inputs and a decoder that could take object (or flat) codes and produce an image. In the second phase (Fig. 3d), we trained the dynamics module to predict the next set of object codes in videos from our training set (using teacher-forcing as detailed in Methods).
We evaluated our models using the VoE paradigm for the five physical concepts targeted in the Physical Concepts test set: continuity, directional inertia, object persistence, solidity and unchangeableness (see Methods for description). We chose these physical concepts to satisfy three criteria. First, we wanted to cover real-world physical phenomena (for example, gravity, solidity, stability and so on), which could be faithfully instantiated in a simulated environment. Second, we chose concepts that had some experimental precedence in the developmental literature. Third, we chose physical concepts that were amenable to the probe construction splicing procedure described below. For a single physical concept, we procedurally generated 5,000 probe tuples, each comprising two physically possible probes and two physically impossible probes. The impossible probes were constructed by splicing (illustrated in Fig. 4) together frames from the possible probes in a way that clearly violates physics. This splicing procedure ensures that the same set of images is present in the possible probes as in the impossible probes. The only difference is the ordering (which yields aphysical events in the impossible probes), an approach pioneered by Riochet et al.28. Furthermore, we splice frames such that all adjacent frames are physically possible, even if the scene as a whole is not. This ensures that the exact same pairs of images appear in both probe types. This precludes a model from showing strong VoE effects merely on the basis of temporally local inconsistencies (see Supplementary Fig. 17 for empirical validation).
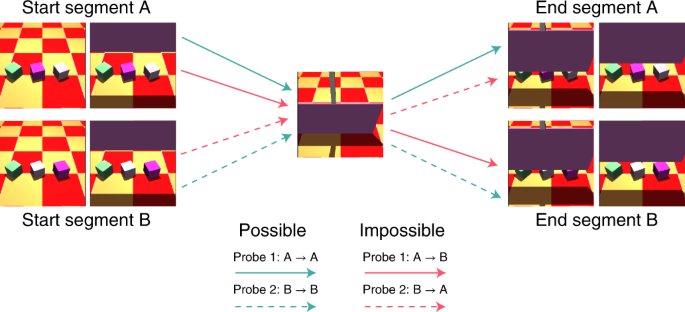
Illustration of the splicing procedure used to create a probe tuple for the physical concept of ‘unchangeableness’ as seen in Supplementary Fig. 4. Probe tuples consist of two possible videos and two impossible videos. The possible videos are created by running a physics engine with related initial conditions (for example, same objects but different positions). Importantly, videos are constructed so that they share a frame in common (centre image). The segments before this shared frame are called the ‘start segments’ (left) and the ones after are called the ‘end segments’ (right). Thus, to create any probe, we can gather frames from a start segment, add the common frame and add frames from an end segment. Possible probes (green arrows) are formed by starting and ending at corresponding start and end segments (for example, start segment A to end segment A). Impossible probes (red arrows) are formed by using a mismatched end segment (for example, start segment A to end segment B). This design ensures that the possible videos and impossible videos within a probe tuple are perfectly matched in terms of individual frames and pairs of frames.
Under the VoE paradigm, physical concept acquisition is quantified by comparing surprise on the two probe types. To calculate surprise for a given video, we compute for each frame the model’s prediction error, defined as the sum-squared error of the system’s pixel-level prediction. Then, we sum prediction errors across all frames within a video. For each of the 5,000 probe tuples for a physical concept, we compute the sum of the surprises on the possible probes, called the physically possible surprise, and similarly compute the physically impossible surprise. We compute an accuracy score where a probe is ‘classified’ correctly if the impossible surprise is greater than the possible surprise. We use the average accuracy to assess the model’s acquisition of a physical concept. Whereas accuracy is binary, we can also compute the relative surprise, the difference between the impossible surprise and possible surprise, to quantify the magnitude of the surprise effect. To allow for comparison across the probe tuples, we normalize the relative surprise by the sum of both the possible and impossible surprises. This normalization takes account of the fact that some initial conditions yield higher baseline surprises across both probe types (for example, probes with higher velocities). Finally, to accommodate variability in simulation results, we computed average accuracy and average relative surprise for five different initial random seeds of each model.
Test set performance
At test time, PLATO displayed robust VoE effects in all five probe categories when trained with five different random seeds each evaluated over 5,000 probe quadruplets. This was evident both in the relative surprise effect, most analogous to the original developmental experiments (Fig. 5 top row, green bars) as well as in classification accuracy (Fig. 5 middle row, green bars).
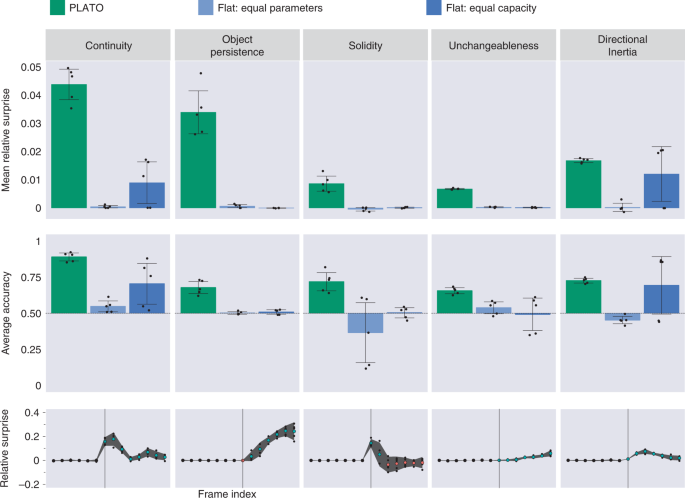
Top, middle rows: Comparison of object-based model PLATO (green) against flat baseline models (blue). PLATO consistently shows large effect sizes (top) in response to impossible events and robustly classifies them as impossible (middle). Even when the flat model has more model parameters (dark blue), it only shows above-chance accuracy on two of the five concepts. Each point represents the average performance over 5,000 probe tuples for models trained with different random seeds. Error bars show the 95% confidence intervals over five seeds, assuming a normal distribution across seeds (although not formally tested). Bottom: frame-by-frame analysis of surprise reveals that the relative surprise increases substantially when videos become physically impossible. The trajectory of this increase is specific to the physical phenomena. For example, in the ‘unchangeableness’ dataset the occluder rises slowly, which yields a gradual increase in relative surprise. In contrast, ‘continuity’ shows a steep peak at the frames where the ball fails to appear between the pillars. Relative surprise is computed at each frame of probe videos for five random seeds of the PLATO model. The x axis indicates frame index within a video. Vertical lines indicate when the impossible probes become aphysical (varies by dataset). Blue and red dots code points above or below zero, respectively, only applied to frames after the onset of aphysicality. Small dots depict different random seeds. Large dots depict mean over three seeds, with corresponding error bars showing 95% confidence intervals over seeds (assuming a normal distribution, but not formally tested).
We performed a one-tailed, single-sample t-test to assess whether the mean relative surprise across seeds was above the chance value of zero. For all five physical concepts, PLATO produced mean (M) relative surprise values above zero: continuity: M = 0.044, s.d. = 0.006, t(4) = 15.9, P = 4.6 × 10−5; directional inertia: M = 0.017, s.d. = 7 × 10−4, t(4) = 47.8, P = 5.7 × 10−7; object persistence: M = 0.034, s.d. = 0.008, t(4) = 8.7, P = 4.8 × 10−4; solidity: M = 0.009, s.d. = 0.003, t(4) = 6.4, P = 0.002; unchangeableness: M = 0.007, s.d. = 2.2 × 10−4, t(4) = 60.57, P = 2.2 × 10−7. Additionally, we performed a one-tailed, single-sample t-test to assess whether the average accuracy was above the chance value of 0.5. For all five physical concepts, PLATO produced accuracy values above 0.5: continuity: M = 0.891, s.d. = 0.028, t(4) = 27.7, P = 5 × 10−6; directional inertia: M = 0.727, s.d. = 0.017, t(4) = 26.9, P = 5.6 × 10−6; object persistence: M = 0.678, s.d. = 0.043, t(4) = 8.2, P = 5.9 × 10−4; solidity: M = 0.719, s.d. = 0.064, t(4) = 6.8, P = 0.001; unchangeableness: M = 0.656, s.d. = 0.021, t(4) = 14.7, P = 6.2 × 10−5. Furthermore, the time courses of relative surprise provided qualitative evidence that surprise rose at the moments in each probe video coinciding with the onset of the relevant physically impossible event (Fig. 5, bottom row).
In contrast, VoE effects were severely diminished or absent for the object-agnostic models (Fig. 5 top and middle rows, blue bars). The strongest results among the object-agnostic models came from the FEC baseline which was matched in representational capacity to PLATO (and thus contained many more free parameters). A one-tailed, single-sample t-test showed that the FEC object-agnostic model produced mean relative surprise above zero (Fig. 5 top row, blue bar) for only three physical concepts: continuity: M = 0.009, s.d. = 0.008, t(4) = 2.4, P = 0.038; directional inertia: M = 0.012, s.d. = 0.01, t(4) = 2.4, P = 0.036; object persistence: M = −3.9 × 10−5, s.d. = 6.4 × 10−5, t(4) = −1.2, P = 0.86; solidity: M = 9.3 × 10−5, s.d. = 2 × 10−4, t(4) = 0.92, P = 0.21; and unchangeableness: M = 1.4 × 10−4, s.d. = 1.3 × 10−4, t(4)=2.15, P = 0.049. A one-tailed, single-sample t-test showed that the FEC model produced accuracy scores (Fig. 5 middle row, blue bar) above zero for only two physical concepts: continuity: M = 0.71, s.d. = 0.15, t(4) = 2.8, P = 0.024; directional inertia: M = 0.69, s.d. = 0.2, t(4) = 1.9, P = 0.065; object persistence: M = 0.51, s.d. = 0.016, t(4) = 1.1, P = 0.168; solidity: M = 0.5, s.d. = 0.036, t(4) = 0.174, P = 0.435; and unchangeableness: M = 0.493, s.d. = 0.115, t(4) = −0.129, P = 0.548.
Taken together, these results indicate a strong facilitative role for object-level representation in the acquisition of intuitive physics concepts, consistent with the conclusions of developmental psychology literature.
Effect of training set size
The training corpus in the Physical Concepts dataset contains a total of 300,000 videos. By a conservative calculation (Methods), this adds up to approximately 52 d worth of continuous visual experience. It is a question of obvious interest, both from an AI and a developmental point of view, how much training data is actually required to yield VoE effects at test. To assess this, we trained three random seeds of PLATO’s dynamics predictor on datasets of gradually decreasing size (Fig. 6), calculating the ‘grand mean’ of VoE effects over all five probe categories (see Supplementary Fig. 12 for metrics on individual probe categories). After training on only 50,000 examples, a one-tailed, single-sample t-test revealed the grand mean relative surprise was above zero (M = 0.02, s.d. = 0.003, t(2) = 9.246, P = 0.006). Similarly, after 50,000 examples we found that the grand mean of PLATO’s accuracy scores was above 0.5 (M = 0.75, s.d. = 0.015, t(2) = 23.3, P = 9.2 × 10−4). These results indicate that robust VoE effects arise in our model after training with as few as 50,000 examples, the equivalent of 28 h of visual experience.
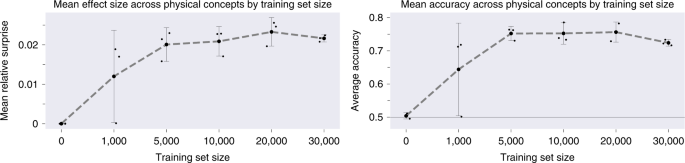
PLATO shows robust VoE effects (left) and accuracy (right) when the dynamics predictor trained with as little as 50,000 examples (28 h of visual experience). Training size = ‘0’ indicates no training at all, shows that object representations are not sufficient for VOE effects and that training the dynamics predictor is critical. Performance was averaged across all five physical concepts. Small dots depict different random seeds. Large dots depict mean over three seeds, with corresponding error bars showing 95% confidence intervals over seeds. Performance across seeds was assumed to be normal, but this was not formally tested.
Generalization to unseen objects and events
As a strong test of generalization, we evaluated our model on object shapes and dynamics different from those presented during training. To do so, we leveraged the ADEPT dataset29, an independently developed, procedurally generated dataset designed to probe intuitive physics knowledge. As detailed under Methods, three probe types from the ADEPT dataset were amenable to the test procedure used in our main simulations. Labelled by their creators ‘overturn short’, ‘overturn long’ and ‘block,’ these probe types include object types not included in our own dataset (for example, rabbits and bowling pins), as well as novel movement patterns (a drawbridge-like plank that rotates not only down but also up). The first two probe types test object permanence using a rotating drawbridge exactly like Baillargeon’s original study13. The third probe tests the concepts of solidity and continuity using a design in a different developmental study11: a rolling ball approaches a wall that should stop it, is briefly occluded before contact, and then is revealed to lie on the opposite side of the wall. This ‘magic trick’ can be viewed as a violation of the principle of solidity (the ball rolled through the wall) or of continuity (the ball teleports to the other side of the wall). We tested PLATO on these probes without retraining or fine-tuning any part of the model, measuring prediction errors for impossible relative to possible probes, as in our original experiments. As shown in Fig. 7, PLATO displayed clear VoE effects for all three probe classes. A one-tailed, single-sided t-test showed that the mean relative surprise was above zero for all three probes: block: M = 0.007, s.d. = 0.002, t(4) = 7.5, P = 8.4 × 10−4; overturn long: M = 0.069, s.d. = 0.011, t(4) = 12.671, P = 1.1 × 10−4; overturn short: M = 0.022, s.d. = 0.016, t(4) = 2.8, P = 0.024. Similarly, PLATO’s accuracy was above 0.5 for all three probes: block: M = 0.765, s.d. = 0.049, t(4) = 10.9, P = 2 × 10−4; overturn long: M = 0.97, s.d. = 0.037, t(4) = 25.3, P = 7.2 × 10−6; overturn short: M = 0.79, s.d. = 0.16, t(4) = 3.56, P = 0.012.
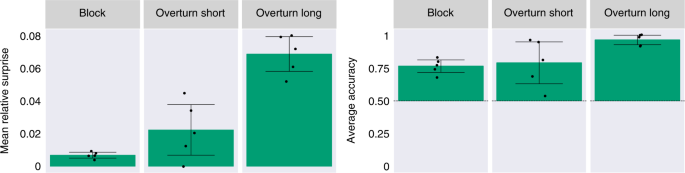
PLATO displays robust VoE effects (left) on unseen objects and dynamics without any retraining. We use videos from three probe types in the ADEPT dataset to assess PLATO’s generalization capabilities. ‘Block’ is designed to test the concepts of solidity and continuity. ‘Overturn short’ and ‘Overturn long’ test the concepts of object permanence. We find reliable VoE effects in both of our metrics. The mean relative surprise (left) varies by probe type but is always above zero, indicating that impossible events are generally more surprising than their possible counterparts. Furthermore, the average accuracy (right) is well above chance (50%, dashed line) for all probe types. Each point represents the average performance over probe pairs for models trained (on our dataset, not ADEPT) with a different random seed. Error bars show the 95% confidence intervals over five seeds. Performance across seeds was assumed to be normal, but this was not formally tested.